

*声明,本文章的参考
Mybatis 3.5.19 源码
技术文章摘抄-深入剖析 MyBatis 核心原理-完
本次主要基于 scripting 包对动态 sql 的整体流程进行一个解析,可能会涉及更多的表述,源码内容稍微少一些。
初始化阶段构建 NodeTree
在应用的启动阶段,MyBatis 会对 xml 文件进行扫描和注册,在扫描过程中,如果见到了 <select> , <update> 等 sql 语句的标签,就会创建一个XMLScriptBuilder 实例,并调用其中的parserScriptNode() 方法完成对应的节点树的组装。
protected MixedSqlNode parseDynamicTags(XNode node) {
// 创建用于存储解析后的 SqlNode 列表
List<SqlNode> contents = new ArrayList<>();
// 获取当前节点的所有子节点
NodeList children = node.getNode().getChildNodes();
// 遍历所有子节点
for (int i = 0; i < children.getLength(); i++) {
// 将子节点包装为 XNode 对象
XNode child = node.newXNode(children.item(i));
// 判断节点类型是否为 CDATA 或文本节点
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
// 获取节点中的文本内容
String data = child.getStringBody("");
// 如果文本内容为空或仅包含空白字符
if (data.trim().isEmpty()) {
// 从缓存中获取或创建 EmptySqlNode 并添加到列表中,然后继续下一次循环
contents.add(emptyNodeCache.computeIfAbsent(data, EmptySqlNode::new));
continue;
}
// 创建 TextSqlNode 对象
TextSqlNode textSqlNode = new TextSqlNode(data);
// 判断文本节点是否包含动态内容(如 ${})
if (textSqlNode.isDynamic()) {
// 如果是动态内容,添加 TextSqlNode 并标记脚本为动态
contents.add(textSqlNode);
isDynamic = true;
} else {
// 如果是静态内容,添加 StaticTextSqlNode
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
// 获取元素节点的标签名
String nodeName = child.getNode().getNodeName();
// 根据标签名获取对应的节点处理器
NodeHandler handler = nodeHandlerMap.get(nodeName);
// 如果找不到对应的处理器,抛出异常
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
// 使用处理器处理该节点,并将结果添加到 contents 列表中
handler.handleNode(child, contents);
// 包含元素节点意味着脚本是动态的
isDynamic = true;
}
}
// 返回包含所有解析后 SqlNode 的 MixedSqlNode
return new MixedSqlNode(contents);
}可以看到,处理的内容大致可以分为三种。
- 静态文本语句,直接创建一个
StaticTextSqlNode - 动态文本语句,将
${}的内容替换后放入textSqlNode,并将这条 sql 语句标记为动态的。 - 含有标签的语句,根据标签名称获取到对应 Handler 类(内部类),然后通过其
handleNode方法完成解析操作并创建相对应的 node 结点。
这里还有一个易混点,当我们遍历到一个标签例如 <if> 时,我们的解析并没有结束,标签内的内容会继续被 parseDynamicTags 结合,可能是一个 StaticTextSqlNode 或者 TextSqlNode ,然后存放到他的 contents 属性中。
以 WhereHandler 为例,这个内部类的写法如下:
private class WhereHandler implements NodeHandler {
public WhereHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 先通过刚才的 parseDynamicTags 解析出来 node,再转换为对应的 node 节点
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
WhereSqlNode where = new WhereSqlNode(configuration, mixedSqlNode);
targetContents.add(where);
}
}其他标签的处理都基本相同,都是先解析再转换的思路。
运行阶段的动态解析和拼接
当需要执行一个 sql 时,进入动态解析的入口是 DynamicSqlSource.getBoundSql():
@Override
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject, null, paramNameResolver, true);
rootSqlNode.apply(context);
String sql = context.getSql();
SqlSource sqlSource = SqlSourceBuilder.buildSqlSource(configuration, sql, context.getParameterMappings());
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
context.getBindings().forEach(boundSql::setAdditionalParameter);
return boundSql;
}其中最重要的就是前两步:
- 创建一个
DynamicContext管理生成完整 sql 时的中间状态。 - 从根节点开始对节点树进行解析,生成完整的 sql 语句。
DynamicContext 是专门用来管理生成 Sql 时的中间状态的,其中有两个成员变量非常重要:
- bindings, 类型是 ContextMap ,继承了 HashMap 的增强式 map,结合前面文章解析过的 MateObject 提供了更强的参数解析能力。
- sqlBuilder,类型是 StringJoiner,每次 node 解析完成后都会上 sqlBuilder 后追加 sql 语句,直到整颗节点树解析完成。
再来看一下 ContextMap 的具体实现:
static class ContextMap extends HashMap<String, Object> {
private static final long serialVersionUID = 2977601501966151582L;
private final MetaObject parameterMetaObject;
private final boolean fallbackParameterObject;
public ContextMap(MetaObject parameterMetaObject, boolean fallbackParameterObject) {
this.parameterMetaObject = parameterMetaObject;
this.fallbackParameterObject = fallbackParameterObject;
}
// 重写了其 get 方法,先从 map 中去找,找不到的话尝试去 parameterMetaObject 中找,实在不行就直接返回入参的原始对象。
@Override
public Object get(Object key) {
String strKey = (String) key;
if (super.containsKey(strKey)) {
return super.get(strKey);
}
if (parameterMetaObject == null) {
return null;
}
if (fallbackParameterObject && !parameterMetaObject.hasGetter(strKey)) {
return parameterMetaObject.getOriginalObject();
}
return parameterMetaObject.getValue(strKey);
}
}上面多次提到了 node ,然后目前我们还没有看 node 长什么样子:
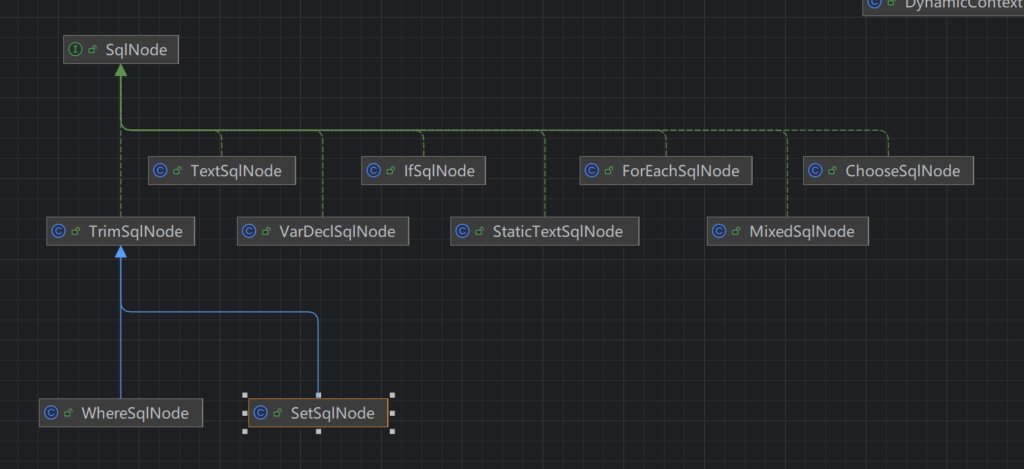
可以看到,他们都继承自 SqlSource 接口,接口中只有一个getBoundSql ,然后让我们再来看几个实现。
IfSqlNode:
public class IfSqlNode implements SqlNode {
private final ExpressionEvaluator evaluator = ExpressionEvaluator.INSTANCE;
private final String test;
private final SqlNode contents;
public IfSqlNode(SqlNode contents, String test) {
this.test = test;
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
}我们知道在 <if> 标签中有一个判断语句,只要判断为 true ,才会添加相关的逻辑,而这里的 test 就是判断语句,其中的 context.getBindings()就包含了参数信息。进入 evaluateBoolean 方法:
public boolean evaluateBoolean(String expression, Object parameterObject) {
Object value = OgnlCache.getValue(expression, parameterObject);
if (value instanceof Boolean) {
return (Boolean) value;
}
if (value instanceof Number) {
return new BigDecimal(String.valueOf(value)).compareTo(BigDecimal.ZERO) != 0;
}
return value != null;
}其中的 OgnlChache 的判断的核心,其中用到 OGNL 来高效的处理值,并提供了一定缓存能力。从这里我们也可以进一步的看出 Bindings 在这里的作用:保留参数信息,供值判断时使用。
从上面的类图中我们可以看到,有一个比较特殊的类 TrimSqlNode ,他还有两个子类 WhereSqlNonde 和 SetSqlNode ,我们已经知道这两个标签可以嵌套其他的标签,那么也就是说, TrimSqlNode 对这个嵌套型的标签做了特殊处理,具体是如何处理的呢,来看一看他的 apply:
@Override
public boolean apply(DynamicContext context) {
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
boolean result = contents.apply(filteredDynamicContext);
filteredDynamicContext.applyAll();
return result;
}他首先创建了一个 FilteredDynamicContext 类,这是一个内部类,继承自 DynamicContext
/**
* 过滤后的动态上下文,用于处理 SQL 的前缀和后缀。
* 该类继承自 DynamicContext,主要功能包括:
* 1. 收集内部 SqlNode 生成的 SQL 片段到缓冲区。
* 2. 在应用所有内部节点后,根据配置去除多余的前缀或后缀。
* 3. 添加配置的前缀和后缀。
* 4. 将处理后的 SQL 追加到委托的上下文中。
*/
private class FilteredDynamicContext extends DynamicContext {
/**
* 委托的动态上下文,最终 SQL 和参数映射将写入此处。
*/
private final DynamicContext delegate;
/**
* 标记前缀是否已应用,确保只应用一次。
*/
private boolean prefixApplied;
/**
* 标记后缀是否已应用,确保只应用一次。
*/
private boolean suffixApplied;
/**
* SQL 缓冲区,用于临时存储内部 SqlNode 生成的 SQL 内容。
*/
private StringBuilder sqlBuffer;
/**
* 构造过滤器动态上下文。
*
* @param delegate 委托的动态上下文
*/
public FilteredDynamicContext(DynamicContext delegate) {
// 调用父类构造函数,初始化基本上下文信息
super(configuration, delegate.getParameterObject(), delegate.getParameterType(), delegate.getParamNameResolver(),
delegate.isParamExists());
this.delegate = delegate;
this.prefixApplied = false;
this.suffixApplied = false;
this.sqlBuffer = new StringBuilder();
// 复制委托上下文中的绑定变量,确保表达式解析时能访问到相同的变量
this.bindings.putAll(delegate.getBindings());
}
/**
* 应用所有前缀和后缀处理逻辑,并将处理后的 SQL 追加到委托上下文中。
* 此方法应在所有内部 SqlNode 执行完毕后调用。
*/
public void applyAll() {
// 去除首尾空白字符,并重新构建 StringBuilder
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
// 获取大写形式的 SQL 用于前缀/后缀匹配(不区分大小写)
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (!trimmedUppercaseSql.isEmpty()) {
// 应用前缀处理(包括去除多余前缀和添加配置前缀)
applyPrefix(sqlBuffer, trimmedUppercaseSql);
// 应用后缀处理(包括去除多余后缀和添加配置后缀)
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
// 将处理后的 SQL 追加到委托上下文中
delegate.appendSql(sqlBuffer.toString());
}
/**
* 追加 SQL 片段到缓冲区。
* 与直接追加到委托上下文不同,这里先缓存到 sqlBuffer 中,以便后续统一处理前缀和后缀。
*
* @param sql 要追加的 SQL 片段
*/
@Override
public void appendSql(String sql) {
// 如果缓冲区已有内容,先添加一个空格作为分隔符
if (sqlBuffer.length() > 0) {
sqlBuffer.append(" ");
}
sqlBuffer.append(sql);
}
/**
* 获取最终的 SQL 字符串。
* 由于实际 SQL 存储在委托上下文中,此处直接委托给 delegate。
*
* @return 最终的 SQL 字符串
*/
@Override
public String getSql() {
return delegate.getSql();
}
/**
* 获取参数映射列表。
* 直接委托给 delegate,因为参数映射是在追加 SQL 时由底层逻辑处理的。
*
* @return 参数映射列表
*/
@Override
public List<ParameterMapping> getParameterMappings() {
return delegate.getParameterMappings();
}
/**
* 应用前缀逻辑。
* 1. 如果配置了 prefixesToOverride,检查 SQL 开头是否包含需要去除的前缀,如果有则去除。
* 2. 如果配置了 prefix,在 SQL 开头添加该前缀。
*
* @param sql 当前 SQL 缓冲区
* @param trimmedUppercaseSql 大写且去空白的 SQL 字符串,用于匹配
*/
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
// 确保前缀只应用一次
if (prefixApplied) {
return;
}
prefixApplied = true;
// 处理需要去除的前缀
if (prefixesToOverride != null) {
// 查找第一个匹配的前缀并去除
prefixesToOverride.stream().filter(trimmedUppercaseSql::startsWith).findFirst()
.ifPresent(toRemove -> sql.delete(0, toRemove.trim().length()));
}
// 添加配置的前缀
if (prefix != null) {
// 在前缀前加一个空格,确保与后续 SQL 分隔
sql.insert(0, " ").insert(0, prefix);
}
}
/**
* 应用后缀逻辑。
* 1. 如果配置了 suffixesToOverride,检查 SQL 结尾是否包含需要去除的后缀,如果有则去除。
* 2. 如果配置了 suffix,在 SQL 结尾添加该后缀。
*
* @param sql 当前 SQL 缓冲区
* @param trimmedUppercaseSql 大写且去空白的 SQL 字符串,用于匹配
*/
private void applySuffix(StringBuilder sql, String trimmedUppercaseSql) {
// 确保后缀只应用一次
if (suffixApplied) {
return;
}
suffixApplied = true;
// 处理需要去除的后缀
if (suffixesToOverride != null) {
// 查找第一个匹配的后缀并去除
suffixesToOverride.stream()
.filter(toRemove -> trimmedUppercaseSql.endsWith(toRemove) || trimmedUppercaseSql.endsWith(toRemove.trim()))
.findFirst().ifPresent(toRemove -> {
// 计算需要删除的起始位置
int start = sql.length() - toRemove.trim().length();
int end = sql.length();
sql.delete(start, end);
});
}
// 添加配置的后缀
if (suffix != null) {
// 在后缀前加一个空格,确保与前序 SQL 分隔
sql.append(" ").append(suffix);
}
}
}也就是说,在处理 TrimSqlNode 是,并不会将结果追加到 DynamicContext 中,而是先存放到 filteredDynamicContext 中,等处理完成后,还会通过 filteredDynamicContext.appAll()对数据进行一波清洗,然后在添加到 DynamicContext 中。而他的两个子类,也只不过是自定义了一下 prefix 标识和清洗时的相关规则,其实现完全采用父类的实现:
public class WhereSqlNode extends TrimSqlNode {
private static final List<String> prefixList = Arrays.asList("AND ", "OR ", "AND\n", "OR\n", "AND\r", "OR\r", "AND\t",
"OR\t");
public WhereSqlNode(Configuration configuration, SqlNode contents) {
super(configuration, contents, "WHERE", prefixList, null, null);
}
}
#{} -> ? 的转变?
在老版本中,都是当所有的 SqlNode.apply() 执行完毕,之后再次对 sql 语句进行一次扫描,通过此词法分析去找到其中 #{} ,并完成替换,但是在最近的版本中,这个过程已经被合并到了 StaticTextSqlNode 和 TextSqlNode 的 apply 方法中
@Override
public boolean apply(DynamicContext context) {
context.appendSql(context.parseParam(text));
return true;
}
protected String parseParam(String sql) {
initTokenParser(getParameterMappings());
return tokenParser.parse(sql);
}
private void initTokenParser(List<ParameterMapping> parameterMappings) {
if (tokenParser == null) {
tokenHandler = new ParameterMappingTokenHandler(parameterMappings != null ? parameterMappings : new ArrayList<>(),
configuration, parameterObject, parameterType, bindings, paramNameResolver, paramExists);
tokenParser = new GenericTokenParser("#{", "}", tokenHandler);
}
}其中的 initTokenParser 就是核心的替换方法。
这种架构上的改变有两个好处:
- 防止误解析(安全性提升): 如果使用老版本后置合并解析的策略,当某个用户在使用
${}动态拼接的一段用户输入字符串里刚好带有#{时,后置的全局解析器会把它错误地识别为 SQL 参数占位符而引发异常;而在现在的设计中,在拼接节点时就能明确限定哪些原本属于#{}表达式,逻辑更加严谨。 - 避免大字符串二次遍历性能损耗: 少了一次拼接完几千行复杂长 SQL 后的全局正则表达式 / Token 二次扫描操作,文本块就近解析并替换,内存利用局部的
StringBuilder提高性能。
Comments NOTHING