

1. 绪论:Java I/O性能的演进与零拷贝的必要性
在构建高性能、高吞吐量的分布式系统时,I/O(输入/输出)操作往往是性能瓶颈的根源。对于Java工程师而言,理解Java虚拟机(JVM)如何与底层操作系统交互,特别是在数据传输环节的机制,是突破性能极限的关键。Java作为一种托管语言,其内存管理机制(堆内存)虽然简化了开发,但也引入了“内存墙”问题——数据在JVM堆内存与操作系统内核缓冲区之间的频繁拷贝,消耗了大量的CPU周期和内存带宽。
零拷贝(Zero-Copy)技术并非单一的API或工具,而是一套旨在消除CPU在数据传输过程中冗余拷贝操作的体系化技术方案。在现代微服务架构、大数据流处理平台(如Apache Kafka)以及高性能通信框架(如Netty)中,零拷贝技术是支撑百万级TPS(每秒事务处理量)的核心基石。本报告将从Java工程师的视角出发,深入操作系统内核原理,剖析Java NIO(New I/O)的源码实现,对比主流中间件的架构选型,并探讨堆外内存管理的复杂性与未来演进。
1.1 传统I/O的性能损耗分析
要理解零拷贝的价值,必须首先解构传统I/O操作的成本。在Java的标准IO包(java.io)中,读取文件并发送到网络是一个看似简单却极其昂贵的操作。
当Java应用执行一次“读文件-写网络”操作时,实际上触发了多次上下文切换(Context Switch)和数据拷贝。CPU不仅要负责逻辑计算,还要充当“搬运工”,将数据在不同的内存区域间复制。
在传统模式下,数据流转路径如下:
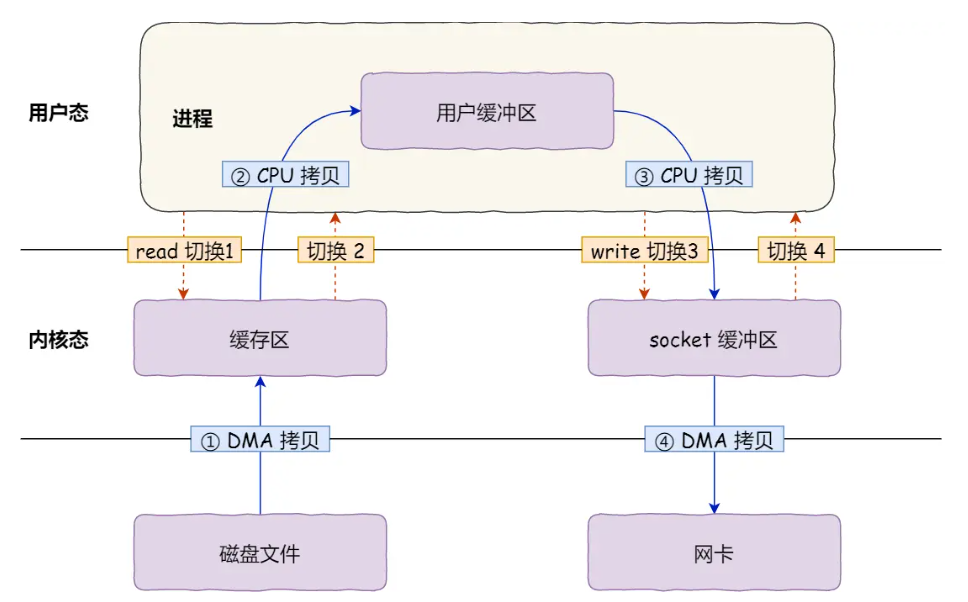
- 硬盘 -> 内核读缓冲区(Read Buffer/Page Cache):由DMA(直接内存访问)引擎执行。
- 内核读缓冲区 -> 用户缓冲区(User Buffer/JVM Heap):由CPU执行,涉及从内核态到用户态的切换。
- 用户缓冲区 -> 内核Socket缓冲区(Socket Buffer):由CPU执行,涉及从用户态到内核态的切换。
- 内核Socket缓冲区 -> 网卡(NIC):由DMA引擎执行。
这一过程不仅占用了宝贵的CPU缓存(L1/L2 Cache),还增加了垃圾回收(GC)的压力,因为用户缓冲区通常是分配在堆上的字节数组。据行业经验法则,处理1比特的输入数据大约需要1个CPU时钟周期,在千兆乃至万兆网络环境下,CPU将不堪重负。
2. 操作系统内核原语:零拷贝的基石
Java的零拷贝能力本质上是对操作系统内核系统调用(System Call)的封装。Linux内核提供了多种零拷贝原语,Java NIO通过JNI(Java Native Interface)暴露了这些能力。
2.1 内存映射(mmap)
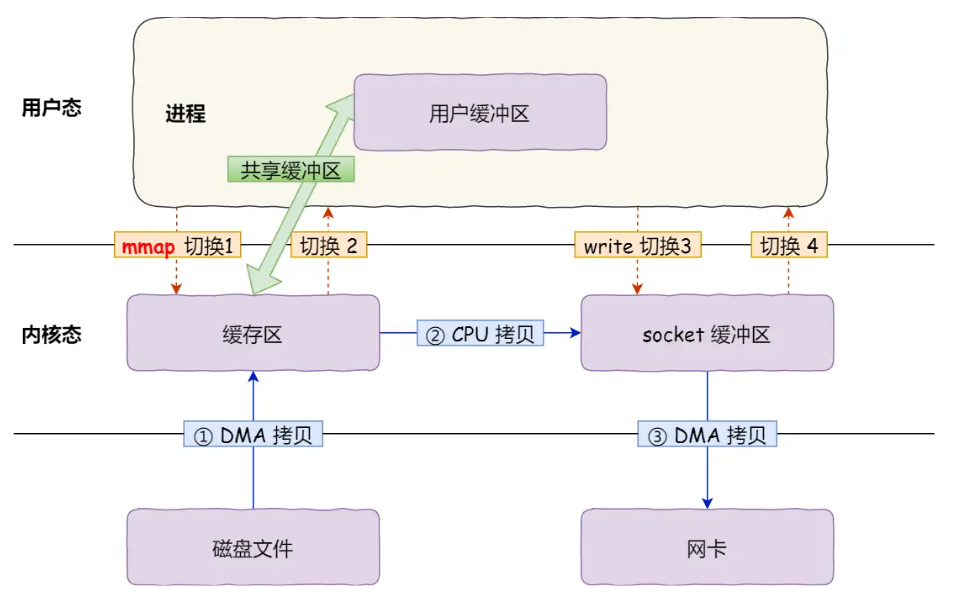
mmap(Memory Mapped Files)是Unix系统中最经典的零拷贝实现之一。它通过将文件描述符(FD)直接映射到用户进程的虚拟地址空间,使得进程可以直接像访问内存一样访问文件内容。
2.1.1 工作原理与优势
当调用mmap时,内核并不会立即将文件数据加载到物理内存中,而是建立虚拟地址与磁盘扇区的映射关系。当应用程序通过指针访问这段地址时,如果数据不在内存中,MMU(内存管理单元)会触发缺页中断(Page Fault),内核随即通过DMA将数据从磁盘加载到页缓存(Page Cache)中。
关键在于,mmap建立的虚拟内存地址与内核的页缓存共享同一块物理内存。因此,当应用程序读取数据时,无需将数据从内核空间复制到用户空间,直接减少了一次CPU拷贝。
2.1.2 局限性
尽管mmap减少了拷贝,但它并没有减少上下文切换的次数。如果应用程序需要将映射的数据写入Socket,依然需要调用write()系统调用,这同样涉及从用户态到内核态的切换。此外,mmap在处理大文件时面临虚拟内存碎片化的问题,且在多进程并发写入时需要复杂的同步机制(如MAP_HASSEMAPHORE)。
2.2 发送文件(sendfile)
Linux 2.1内核引入了sendfile系统调用,旨在简化网络文件传输。其函数原型为 ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count)。
2.2.1 标准sendfile机制
在标准sendfile调用中,数据直接从磁盘读取到页缓存,然后由CPU从页缓存复制到Socket缓冲区。由于整个过程都在内核空间完成,数据从未进入用户空间,因此完全避免了内核与用户空间之间的数据拷贝。这就将上下文切换次数从传统的4次降低到了2次。
2.2.2 带有Scatter/Gather DMA的sendfile
Linux 2.4内核对sendfile进行了进一步优化,结合硬件的Scatter/Gather(分散/收集)DMA特性,实现了真正的“零CPU拷贝”。
在此模式下:
- DMA将数据从磁盘拷贝到页缓存。
- CPU不再复制数据本身,而是将数据的描述符(内存地址和长度)写入Socket缓冲区。
- 网卡的DMA引擎根据Socket缓冲区中的描述符,直接从页缓存读取数据进行发送。
这是目前Linux环境下文件传输性能的天花板,也是Kafka等高吞吐系统的核心依赖。
2.3 拼接(splice)
splice系统调用在Linux 2.6.17中引入,允许在两个文件描述符之间移动数据,而无需拷贝到用户空间,前提是其中一个描述符必须是管道(Pipe)。这为实现基于管道的高性能代理服务器提供了可能,尽管在Java生态中直接使用splice的场景较少,但Netty正在通过io_uring等新技术探索其潜力。
2.4 比较分析
为了更直观地理解不同技术的差异,下表总结了各模式的开销:
| I/O 模式 | 系统调用 | 上下文切换次数 | CPU 拷贝次数 | DMA 拷贝次数 | 适用场景 |
| 传统 I/O | read + write | 4 | 2 | 2 | 需要对数据进行复杂处理(如加密、压缩) |
| mmap + write | mmap + write | 4 | 1 | 2 | 需要频繁随机读取文件内容,小文件读写 |
| sendfile | sendfile | 2 | 1 | 2 | 静态文件传输,无需修改数据 |
| sendfile (DMA Gather) | sendfile | 2 | 0 | 2 | 高性能网络传输,网卡支持SG-DMA |
3. Java NIO深度解析:源码级实现与陷阱
Java NIO库(java.nio)是Java实现零拷贝的门户。然而,NIO的抽象层掩盖了许多底层细节,若使用不当,不仅无法提升性能,反而可能导致内存泄漏或性能退化。
3.1 FileChannel.transferTo():Java版的sendfile
FileChannel类的transferTo()方法是Java对sendfile系统调用的直接封装。
public abstract long transferTo(long position, long count, WritableByteChannel target)3.1.1 实现机制
在OpenJDK的Linux实现中,transferTo最终会调用native方法。如果底层操作系统支持(如Linux Kernel 2.1+),它会映射到sys_sendfile。这使得Java程序能够利用内核的页缓存机制,将文件数据直接推送到网络堆栈,而无需将字节加载到JVM堆中。
3.1.2 性能收益与限制
这种机制对于静态资源服务器(如Web服务器伺服图片、CSS文件)极其高效。因为它避免了数据在JVM堆中的分配和回收,极大地降低了GC压力。然而,transferTo有一个致命的限制:数据的不可变性。由于数据不经过用户空间,Java代码无法查看或修改数据。这意味着如果应用层需要对数据进行SSL/TLS加密、压缩或内容过滤,就无法直接使用transferTo,必须退回到传统的读取-处理-写入模式,这解释了为什么开启SSL/TLS往往会使Kafka等系统的零拷贝失效。
3.2 MappedByteBuffer:Java版的mmap
MappedByteBuffer是通过FileChannel.map()创建的。它是ByteBuffer的一个子类,其背后的存储空间位于堆外(Off-Heap)。
3.2.1 虚拟内存魔法
当创建一个MappedByteBuffer时,JVM调用底层的mmap系统调用。此时,Java对象(DirectByteBuffer)仅仅维护了一个指向内核空间的内存地址(address)和容量(capacity)。对这个Buffer的读写操作,实际上是直接对虚拟内存的操作。操作系统负责根据缺页中断机制,将磁盘文件的数据按页加载到物理内存中。
3.2.2 堆外内存的回收难题
Java的垃圾回收器(GC)主要管理堆内存。对于MappedByteBuffer,GC只能回收堆上的包装对象(即DirectByteBuffer实例),而无法直接释放底层的操作系统内存映射。
在JDK 21之前,释放MappedByteBuffer占用的文件句柄是一个著名的痛点。由于mmap映射的生命周期不由GC直接控制,如果Java进程频繁创建映射而不释放,会导致文件句柄耗尽或本地内存溢出。
传统的(且不安全的)解决方案是利用反射调用sun.misc.Cleaner:
((DirectBuffer) buffer).cleaner().clean();
这种做法依赖于非公开API,存在兼容性风险。但这是RocketMQ等中间件为了防止内存泄漏必须采用的手段。
3.3 IOUtil与临时直接缓冲区的陷阱
这是Java NIO中一个极易被忽视的性能杀手。当开发者使用非直接缓冲区(HeapByteBuffer,即基于数组的缓冲区)进行I/O操作(如SocketChannel.write(heapBuf))时,JVM无法直接将堆内存地址传递给内核系统调用。
原因: 堆内存是受GC管理的,GC可能会在系统调用执行期间移动对象(如在Survivor区之间复制),导致物理地址发生变化。
后果: 为了解决这个问题,JVM内部的IOUtil类会自动分配一个临时的直接缓冲区(Temporary Direct Buffer)。
- JVM申请一块临时的堆外内存。
- 将HeapByteBuffer中的数据拷贝到这块临时堆外内存中。
- 使用这块堆外内存的地址执行系统调用。
- 操作完成后,释放或缓存这块临时内存 19。
这意味着,如果你为了“方便”而一直使用HeapByteBuffer进行高频I/O,实际上你并没有避开拷贝,反而增加了一次隐式的堆内到堆外的拷贝,且增加了直接内存分配的开销。
优化策略: jdk.nio.maxCachedBufferSize参数用于限制这些线程本地临时缓存的大小。在JDK 8u102之前,这个缓存是无上限的,曾导致许多难以排查的OOM(Out Of Memory)错误 20。
4. Netty框架:用户态零拷贝与内核态零拷贝的融合
Netty作为Java高性能网络编程的事实标准,其“零拷贝”概念比操作系统的定义更为广泛。它在用户态(JVM层面)和内核态(系统调用层面)双管齐下。
4.1 用户态零拷贝:CompositeByteBuf
在处理网络协议时,经常需要将多个数据包合并,或者将协议头与消息体拼接。传统的做法是创建一个新的大字节数组,将两部分数据拷贝进去。
Netty引入了CompositeByteBuf,它是一个虚拟的Buffer,内部持有多个物理Buffer的引用。当用户读取CompositeByteBuf时,Netty负责计算索引,直接从对应的组件Buffer中读取数据。
优势: 实现了逻辑上的拼接,物理上零拷贝。这在协议编解码(Codec)阶段极大地减少了内存复制和对象创建 22。
4.2 零拷贝视图:Slice与Duplicate
ByteBuf提供了slice()和duplicate()方法。
- slice():创建一个新的
ByteBuf对象,共享原始Buffer的内存区域,但拥有独立的读写指针。常用于将一个大包拆解为多个子包处理。 - duplicate():完全共享内存和内容的副本。
这两种操作都只是创建了轻量级的对象头,底层数据没有任何复制。
4.3 对FileRegion的支持
Netty通过FileRegion接口(通常是DefaultFileRegion实现类)支持FileChannel.transferTo()。当在Netty的Pipeline中写入一个FileRegion对象时,Netty的AbstractNioByteChannel会检测到该类型,并直接调用JDK的transferTo方法,从而触发内核的sendfile机制,实现真正的文件传输零拷贝。
5. 架构案例分析:Kafka与RocketMQ的零拷贝之争
Apache Kafka和Apache RocketMQ作为两款顶级的消息中间件,在零拷贝技术的选型上代表了两种不同的设计哲学。
5.1 Apache Kafka:吞吐量至上的sendfile流派
Kafka的设计目标是极致的吞吐量,主要用于日志收集和流式处理。
5.1.1 核心机制
Kafka Broker在处理消费者拉取请求时,通过FileChannel.transferTo直接将日志段文件(Log Segment)的数据发送到网络Socket。
- 数据流向: 磁盘 -> 页缓存 -> 网卡。
- 优势: 极高的数据传输效率,充分利用操作系统的预读(Readahead)机制。
- 代价: Broker对消息内容几乎是“盲”的。Kafka难以在Broker端进行复杂的单条消息过滤(如基于消息体的Tag过滤),因为这需要将数据读回用户空间解析,破坏零拷贝路径。
5.1.2 零拷贝的失效场景
当Kafka启用了SSL/TLS加密时,transferTo失效。因为内核(在没有kTLS支持的情况下)无法处理加密逻辑,数据必须拷贝到用户空间进行加密计算。这会导致显著的性能下降和CPU使用率飙升。
5.2 Apache RocketMQ:低延迟与灵活性的mmap流派
RocketMQ定位于业务级消息队列,支持复杂的消息过滤、事务消息和定时消息,对延迟的稳定性要求极高。
5.2.1 核心机制
RocketMQ大量使用mmap(通过MappedByteBuffer)来操作CommitLog和ConsumeQueue。
- 存储结构: 所有消息顺序写入CommitLog,同时异步构建ConsumeQueue索引。
- 优势: 应用层可以直接访问映射的内存,能够轻松读取消息头进行Tag过滤、属性检查等逻辑判断。同时,
mmap使得写入操作变为内存操作,极大降低了写入延迟。
5.2.2 1GB文件大小限制的深层原因
RocketMQ严格将MappedFile的大小限制在1GB(默认)。这并非随意设定,而是基于深入的考量:
- 虚拟内存碎片:在32位系统时代,进程的地址空间有限(用户态仅2GB-3GB),很难找到连续的大块虚拟地址空间。虽然64位系统解决了地址空间问题,但过大的映射文件会增加内核管理页表(Page Table)的开销。
- 预热成本:
mmap建立映射后,并未实际加载数据。如果文件过大,首次访问引发的缺页中断风暴(Page Fault Storm)会导致严重的性能抖动。 - 安全性与恢复:较小的文件粒度有利于原子性的刷盘(flush)和故障恢复,减少系统崩溃时的数据丢失风险。
5.2.3 预热(Pre-touch)与内存锁定
为了解决mmap的懒加载导致的首次访问延迟,RocketMQ实现了一种“文件预热”机制。在创建MappedFile后,它会尝试:
- madvise:建议内核预读取数据。
- Pre-touch:每隔4KB(一个页的大小)写入一个字节(通常是0)。这强制内核为每一页分配物理内存并建立映射关系。
- mlock(可选):尝试将内存页锁定在物理内存中,防止被交换(Swap)出磁盘。
6. 堆外内存管理与JDK的演进
对于Java工程师,使用零拷贝往往意味着要与Direct Memory(直接内存)打交道。这是一把双刃剑:它提供了高性能,也带来了管理风险。
6.1 Unsafe类的双刃剑
在JDK 21之前,sun.misc.Unsafe是操作堆外内存的核心工具。它提供了allocateMemory、freeMemory等类似于C语言malloc/free的接口。
DirectByteBuffer通过Unsafe分配内存,并注册一个Cleaner(基于虚引用PhantomReference)。当DirectByteBuffer对象被GC回收时,虚引用被触发,Cleaner线程执行Unsafe.freeMemory。
风险点: 如果堆内存充足,GC迟迟不运行,而堆外内存已经耗尽,会导致OutOfMemoryError: Direct buffer memory。这是Netty等框架自己管理内存池(PooledByteBufAllocator)的主要原因之一——手动引用计数,手动释放,不依赖GC。
6.2 Project Panama与MemorySegment:未来已来
JDK 21正式推出了外部函数与内存API(Foreign Function & Memory API, JEP 454),彻底改变了这一局面。
MemorySegment和Arena类提供了安全、确定性的堆外内存管理方式。
// JDK 21 示例:使用Arena管理mmap生命周期
try (Arena arena = Arena.ofConfined()) {
MemorySegment segment = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, size, arena);
// 使用segment进行读写...
} // try-with-resources块结束时,Arena自动释放,确定性地unmap文件
这一机制废弃了对Unsafe和Cleaner的依赖,解决了困扰Java社区二十年的mmap无法安全释放的问题 34。
7. 性能调优与故障排查指南
在生产环境中落地零拷贝技术,仅仅调用API是不够的,还需要全链路的调优。
7.1 JVM参数调优
| 参数 | 作用 | 建议 |
-XX:MaxDirectMemorySize | 限制DirectByteBuffer的最大堆外内存 | 默认等于最大堆大小。建议显式设置,预留足够的Native内存给Netty/NIO。 |
-Djdk.nio.maxCachedBufferSize | 限制IOUtil临时DirectBuffer的大小 | 防止因大文件传输导致的线程本地内存泄漏。建议设置为256KB或更小 21。 |
-XX:+DisableExplicitGC | 禁用System.gc() | 慎用。如果在使用了NIO DirectBuffer的系统中禁用显式GC,可能导致堆外内存无法回收(因为Cleaner依赖System.gc触发Full GC来回收虚引用)。Netty通过-Dio.netty.noPreferDirect=true或显式管理内存来规避此问题。 |
7.2 操作系统参数调优
- vm.swappiness:设置为1或10。零拷贝高度依赖页缓存,如果页缓存被Swap到磁盘,性能将发生雪崩。
- vm.dirty_ratio 和 vm.dirty_background_ratio:控制脏页(Dirty Page)的回写策略。过高的脏页比例会导致刷盘时的IO阻塞(Stop-the-world),影响Kafka/RocketMQ的写入延迟。
7.3 监控手段
- NMT (Native Memory Tracking):使用
-XX:NativeMemoryTracking=detail启动应用,通过jcmd <pid> VM.native_memory查看Native内存分布,排查Direct Buffer泄漏。 - JMX:监控
java.nio:type=BufferPool,name=directBean,获取当前直接内存的使用量和Buffer数量。 - Netty Leak Detector:在开发测试环境开启
-Dio.netty.leakDetection.level=PARANOID,Netty会追踪ByteBuf的分配与释放,报告未释放的缓冲区。
8. 结论与展望
零拷贝技术是Java高性能工程皇冠上的明珠。它打破了高级语言与底层硬件之间的隔阂,使得Java应用能够以接近C++的效率处理海量数据。
对于Java工程师而言,掌握零拷贝不仅仅是学会使用transferTo或mmap,更意味着:
- 理解数据流向:清晰地知道每一个字节在内存、总线和磁盘间的移动路径。
- 权衡架构选型:在Kafka式的极致吞吐(sendfile)与RocketMQ式的低延迟灵活处理(mmap)之间做出符合业务需求的选择。
- 敬畏直接内存:堆外内存赋予了自由,也带来了责任。必须谨慎处理内存的分配与回收,避免隐性的内存泄漏。
展望未来,随着io_uring异步I/O接口的成熟以及Kernel TLS的普及,Java的零拷贝技术将进入一个新的阶段。io_uring有望彻底解决Linux下的异步文件I/O问题,而kTLS将让加密通信重新回归零拷贝的快车道。Java工程师应当持续关注这些底层技术的演进,以便在下一代系统架构中保持竞争力。
Comments NOTHING